An AI’s ability to keep a conversation on track and process info depends directly on its "context window." On Tess AI or any other platform, getting how this window works is key to making the most of your interactions—whether you're chatting, going through docs, or building agents. This article breaks down what context windows and tokens are, plus how you can manage them to get the best results on the platform.
Every time you interact with an AI model, it happens inside a "context window." Think of it like the AI’s short-term memory during a conversation or a certain task. This memory is measured in tokens. Tokens aren’t just words—they’re bits of text that the models use to process and make sense of language. A word can be a token, part of a token, or even several tokens, depending on how complex it is or which language you’re using.
Each AI model available on Tess AI, like the different GPT or Gemini versions, has a max token capacity for its context window. For example, the GPT-4.1 Nano model can handle up to 1 million tokens, while GPT-4o Mini handles 128,000 tokens—and some Gemini models can go all the way up to 2 million tokens.
Just keep in mind that the token count includes both your inputs (questions, instructions, files you upload) and the outputs created by the AI (answers, generated text).
When the number of tokens in an interaction gets close to or goes over the selected model's context window limit, the AI might start showing unexpected behavior. This can include losing earlier conversation info, less coherent answers, or what people often call "hallucination" (making up incorrect information).
To help users, Tess AI shows a warning when the conversation is getting too long and is nearing the context window limit, suggesting you start a new chat.
Step by Step: Checking a Model's Context Window
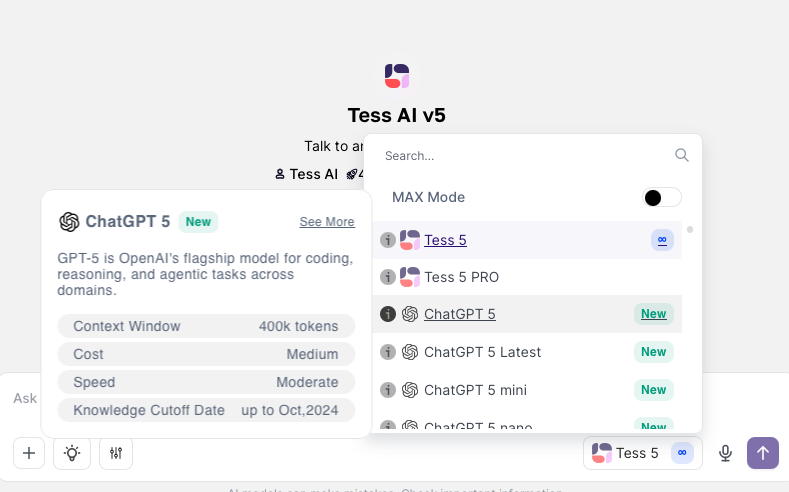
In the AI Copilot conversation area, click the model selector.
Next to the name of the model you want, you'll see a small info icon (an "i" inside a circle).
Click this icon to see the model details, including its "Context Window" in tokens.
Tip: If you expect a long interaction or need to provide a bunch of info, go with models that have bigger context windows right from the start.
One of the cool features of Tess AI is being able to analyze files—like PDFs, spreadsheets (Sheets, Excel), and documents (Docs). The way you upload these files to the Knowledge Base directly affects how the context window is used.
When you add a file to the Knowledge Base, you'll find two main options in the "Context Mode":
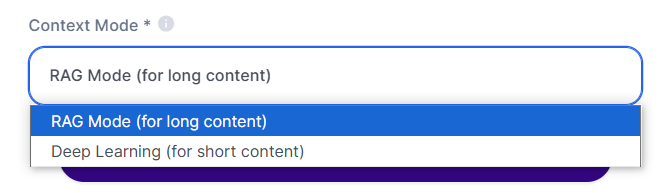
Deep Learning Mode:
Ideal for: Smaller files (e.g.: short PDFs).
How it works: The AI reads through the whole file at once, bringing all the content into the context.
Credit usage: Happens just once, right when the whole file is read in (around 20 credits).
Impact on context window: The entire file's content will take up a chunk of the model's context window.
RAG Mode (RAG - Retrieval Augmented Generation):
Ideal for: Large files (e.g.: long PDFs, big spreadsheets).
How it works: The AI splits the file into multiple "chunks". When you ask a question, it searches and checks only the chunks that matter for the answer, instead of loading the whole file every time.
Credit usage: Happens on each question that needs to search and analyze file chunks. (usually pretty low)
Impact on context window: Way more efficient for big files, since only the relevant chunks are loaded into context at question time, keeping most of the window free for chatting.
Best Practice: For short documents and quick analyses, Deep Learning might be enough. For large documents or when you need to reference specific parts of a big material multiple times, RAG Mode is the most strategic choice, since it optimizes the use of the context window and can potentially save you credits in the long run.
If you often do repetitive tasks that require a specific set of instructions or knowledge, or if your conversations tend to go on for too long and hit context limits, creating an AI Agent in AI Studio is a great solution.
When you create an agent, you give it detailed instructions (prompt) and can even attach specific knowledge bases to it, all at once. This initial “training” is stored in the agent.
How does this help with the context window? Every new chat you start with your custom agent kicks off with a “clean” context window for the interaction itself, but the agent already has all the knowledge and guidelines you set up. That means you don't have to repeat long instructions every time you start a conversation, saving tokens and keeping things shorter and more focused.
To learn how to create an agent, check out our other article!
If, even with the strategies above, you hit the context limit in a chat and the AI suggests starting a new conversation, the current conversation history doesn't get transferred automatically.
Workaround:
Copy the most important parts of your previous chat.
Start a new chat, preferably with an AI model that has a bigger context window.
Paste the copied history into the new chat to give the AI the needed context.
Looking to the Future: Tess AI has developed an awesome feature called "Tess Memories" that lets you save information and specific contexts to reuse across different chats, making it easier to keep things going and personalize your interactions without having to copy and paste by hand.
It's definitely worth trying!
