In this tutorial, I'll explain how to use the Advanced Step "Extract Text from Entire PDF" on the Tess AI platform. This step is useful for getting text out of a PDF, letting you use it to train your model or check the document. Here are the details on how to fill out the fields and some example use cases:
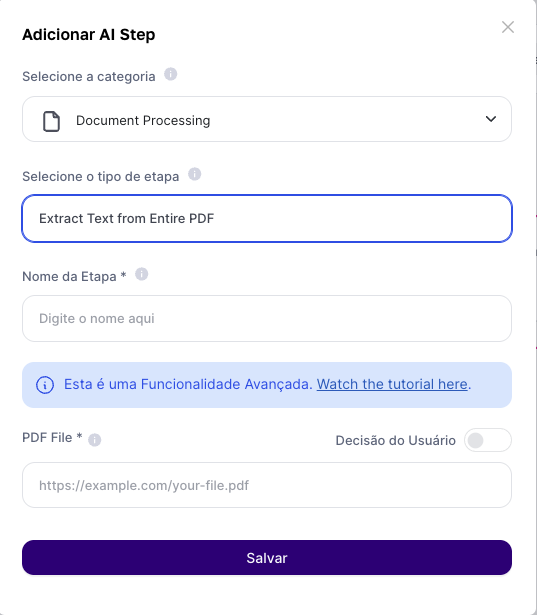
Fill Fields:
Insert PDF file or link: In this field you need to give the link to a PDF file that’s been published on the internet and is accessible. Alternatively, you can use the result from the "Upload File" user input to extract data from files saved on your computer.
Output Result:
All the text from the PDF will be extracted.
Use Cases:
Contract Import for Search: Imagine you have a library of contracts in PDF format. Using the step "Extract Text from Entire PDF", you can extract the text from all these contracts and set up a search model that lets users look for specific terms in the contracts. This helps you find important info quickly.
Import Knowledgebases for Search: If you have a knowledge base in PDF format, you can use this step to extract the content from all documents and make it available in a search system. Users can then search and get relevant info effectively.
Import Documents to Train for Different Markets: If you're training an AI model for a specific market like finance, law, or healthcare, you can use the step "Extract Text from Entire PDF" to collect data from relevant PDF documents. This data can be used to train the model and boost its market understanding, letting it give more accurate and contextual info.
Limitations:
Keep in mind that training your AI based on PDF documents extracted using Tess AI has a size limit.
Training can't go over 80,000 words. So, make sure the PDF you pick is within that limit. If you have a PDF with more than 80,000 words, think about splitting it into smaller parts or just picking the most important sections.
Otherwise, it's better to use the Creation GPT mode by adding the file as RAG.
Conclusion
In short, the "Extract Text from Entire PDF" step is a powerful tool that lets you pull text from PDFs for all sorts of things, from contract searches to training models in different areas. It makes it way easier to grab data from PDF documents and use that info in your workflow.
