La capacidad de una IA para mantener una conversación coherente y procesar información depende directamente de su "ventana de contexto". En Tess AI o en cualquier otra plataforma, entender cómo funciona esta ventana es clave para aprovechar al máximo tus interacciones, ya sea en chats directos, analizando documentos o creando agentes. Este artículo explora el concepto de ventanas de contexto, tokens y cómo puedes gestionar estos elementos para obtener los mejores resultados en la plataforma.
Cada interacción con un modelo de IA ocurre dentro de una "ventana de contexto". Piensa en ella como la memoria a corto plazo de la IA durante una conversación o tarea específica. Esta memoria se mide en tokens. Los tokens no son simplemente palabras; son unidades de texto que los modelos de IA usan para procesar y entender el lenguaje. Una palabra puede ser un token, parte de un token, o varios tokens, dependiendo de su complejidad y del idioma.
Cada modelo de IA disponible en Tess AI, como las variantes de GPT o Gemini, tiene una capacidad máxima de tokens para su ventana de contexto. Por ejemplo, el modelo GPT-4.1 Nano puede soportar hasta 1 millón de tokens, mientras que el GPT-4o Mini soporta 128.000 tokens y algunos modelos Gemini pueden llegar hasta 2 millones de tokens.
Es importante notar que ese conteo de tokens incluye tanto tus entradas (preguntas, instrucciones, archivos enviados) como las salidas generadas por la IA (respuestas, textos creados).
Cuando la cantidad de tokens en una interacción se acerca o supera el límite de la ventana de contexto del modelo seleccionado, la IA puede empezar a mostrar comportamientos inesperados. Esto puede incluir la pérdida de información anterior de la conversación, respuestas menos coherentes, o lo que popularmente se llama "alucinación" (generación de información incorrecta).
Para ayudar a los usuarios, Tess AI implementó un aviso que aparece cuando la conversación se está haciendo muy larga y va llegando al límite de la ventana de contexto, sugiriendo abrir un chat nuevo.
Paso a Paso: Cómo checar la Ventana de Contexto de un Modelo
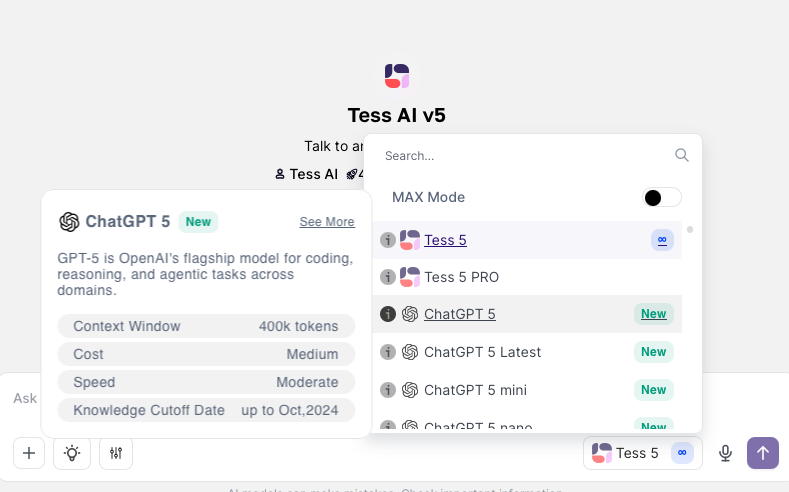
En el AI Copilot, en el área de conversación, haz clic en el selector de modelos.
Al lado del nombre del modelo que quieres, verás un pequeño ícono de información (una "i" dentro de un círculo).
Haz clic en ese ícono para ver los detalles del modelo, incluyendo su "Context Window" (Ventana de Contexto) en tokens.
Consejo: Si esperas una charla larga o tienes que dar un montón de información, elige modelos con ventanas de contexto más grandes desde el principio.
Una de las cosas más chéveres de Tess AI es que puede analizar archivos como PDFs, hojas de cálculo (Sheets, Excel) y documentos (Docs). La manera en que subes estos archivos a la Base de Conocimiento afecta directamente el uso de la ventana de contexto.
Al agregar un archivo a la Base de Conocimiento, vas a ver dos opciones principales en el "Modo de Contexto":
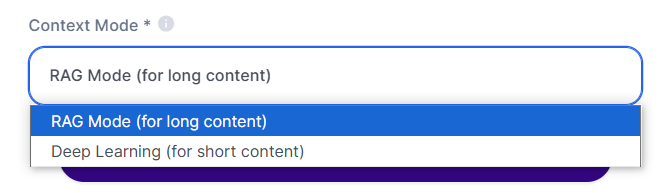
Modo Deep Learning:
Ideal para: Archivos pequeños (ej: PDFs de pocas páginas).
Cómo funciona: La IA lee el archivo por completo de una sola vez, metiendo todo su contenido en el contexto.
Consumo de créditos: Sólo ocurre una vez, al leer el archivo completo (más o menos 20 créditos)
Impacto en la ventana de contexto: Todo el contenido del archivo va a ocupar una parte de la ventana de contexto del modelo.
Modo RAG (RAG - Retrieval Augmented Generation):
Ideal para: Archivos grandes (ej: PDFs largos, hojas de cálculo enormes).
Cómo funciona: La IA divide el archivo en varios "pedazos" (chunks). Cuando haces una pregunta, la IA busca y analiza solo los fragmentos relevantes para responderte, en vez de procesar el archivo entero en cada interacción.
Consumo de créditos: Pasa cada vez que haces una pregunta que requiere buscar y analizar partes del archivo. (generalmente muy bajo)
Impacto en la ventana de contexto: Mucho más eficiente para archivos grandes, porque sólo los fragmentos relevantes se cargan en el contexto en el momento de la pregunta, dejando casi toda la ventana libre para la interacción.
Mejor práctica: Para documentos cortos y análisis rápidos, el Deep Learning puede ser suficiente. Para documentos voluminosos o cuando necesitas consultar partes específicas de un material extenso repetidamente, el Modo RAG es la opción más estratégica, ya que optimiza el uso de la ventana de contexto y, potencialmente, el consumo de créditos a largo plazo.
Si sueles hacer tareas repetitivas que requieren un conjunto específico de instrucciones o conocimiento, o si tus conversaciones tienden a extenderse demasiado, llegando a los límites de contexto, crear un Agente de IA en el AI Studio es una solución genial.
Al crear un agente, le das instrucciones detalladas (prompt) y hasta puedes adjuntar bases de conocimiento específicas para él una sola vez. Ese "entrenamiento" inicial queda guardado en el agente.
¿Cómo ayuda esto con la ventana de contexto? Cada nuevo chat que comiences con tu agente personalizado arranca con una ventana de contexto "limpia" para la interacción en sí, pero el agente ya tiene todo el conocimiento y las directrices que configuraste. Esto significa que no tienes que repetir instrucciones largas en cada conversación nueva, ahorrando tokens y manteniendo las interacciones más cortas y al grano.
Para aprender a crear un agente, accede a nuestro otro artículo!
Si, incluso con las estrategias de arriba, llegas al límite de contexto en un chat y la IA sugiere empezar una nueva conversación, el historial de la conversación actual no se transfiere automáticamente.
Solución temporal:
Copia las partes más importantes de tu conversación anterior.
Inicia un nuevo chat, de preferencia con un modelo de IA que tenga una ventana de contexto más grande.
Pega el historial copiado en el nuevo chat para darle el contexto necesario a la IA.
Mirando al Futuro: Tess AI está desarrollando una función increíble llamada "Tess Memories", que te permite guardar información y contextos específicos para reutilizarlos en diferentes chats, haciendo que seguir y personalizar tus conversaciones sea mucho más fácil, sin tener que copiar y pegar todo a mano.
¡Vale la pena probarlo!
