La capacidad de interactuar con tus propios documentos es una de las funciones más potentes de Tess AI, permitiendo que la IA entienda y use información específica de tu contexto. El chat de IA de la plataforma te da la opción de agregar archivos a tu base de conocimiento, convirtiéndolos en fuentes ricas para respuestas más precisas y personalizadas.
Este artículo detalla cómo puedes agregar, configurar y optimizar el uso de documentos dentro del Chat, explorando los diferentes tipos de archivos soportados y los modos de procesamiento que aseguran el mejor rendimiento para cada situación.
El Chat de Tess AI centraliza varios modelos de IA en una sola interfaz. Para empezar a trabajar con documentos, el primer paso es acceder a esta herramienta.
Paso a paso para agregar documentos:
En el panel de Tess AI, abre un nuevo chat o entra a algún chat de tu historial.
Busca el botón "Adicionar Fotos e Arquivos", representado por un ícono de +, cerca del área de escritura del chat.
Al hacer clic en este botón, se abrirá una ventana para que elijas el tipo de documento que quieres añadir.
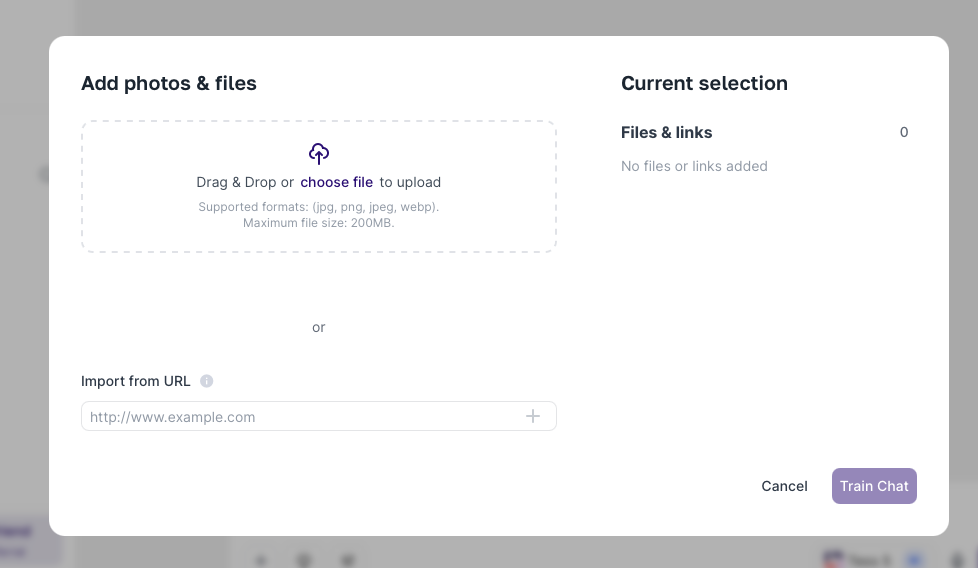
Tess AI soporta un montón de formatos de archivo, incluyendo por ejemplo:
Audio (ej: MP3, WAV)
CSV (Valores Separados por Coma)
Código (varios lenguajes)
DOCX (Microsoft Word)
Excel (XLSX)
Google Sheets (por URL)
Imagen (ej: JPG, PNG)
PDF (Portable Document Format)
TXT (Texto Plano)
Web Scraper (Extracción de contenido de URLs)
Cuando agregas un documento, Tess AI usa herramientas especializadas para extraer el texto que está dentro de él. Por ejemplo, para archivos de audio, se usa una herramienta de transcripción; para PDFs y DOCX, se aplican herramientas de extracción de texto.
Este proceso de extracción inicial puede consumir una pequeña cantidad de créditos, incluso con modelos de IA ilimitados, porque la extracción en sí no es una función de la IA, sino una etapa previa. Una vez extraído, el texto queda guardado y disponible para consulta por la IA sin costos extra por consulta.
Además, el costo por procesar los mismos archivos solo se cobra la primera vez. O sea, si tienes que agregar un archivo que ya subiste y procesaste en Tess en otro chat, no se descontará de tus créditos.
Cada tipo de archivo tiene configuraciones particulares que aparecen después de elegirlo. Por ejemplo:
Excel (XLSX): Vas a necesitar especificar el archivo para subir y el "Range", es decir, la hoja y el rango de celdas que la IA debe leer (ej: "Planilha1!A1:Z100"). No se pueden leer todas las hojas al mismo tiempo.
Audio: Además del archivo, podés elegir la IA de transcripción que quieras (ej: Deepgram, OpenAI Audio, AssemblyAI) y el idioma del audio.
Google Sheets: Se agrega poniendo la URL de la hoja, que tiene que tener permiso de acceso público o para el usuario de Tess AI.
La mayoría de las configuraciones tiene un icono de info ("i") al lado, que te da una explicación breve de para qué sirve.
Una de las opciones más importantes de Tess AI cuando trabajás con documentos es el "Modo de Contexto". Esta opción, en general no disponible en otras plataformas de IA, deja que definas cómo la IA va a procesar e interactuar con el contenido de tu documento. Antes de contarte sobre los modos, es clave entender el concepto de "Ventana de Contexto".
Entendiendo la ventana de contexto: Toda IA tiene una "ventana de contexto", que es la cantidad máxima de información (medida en "tokens" – pequeñas unidades de texto, no necesariamente caracteres o palabras completas) que puede procesar y "recordar" de una sola vez durante una conversación o análisis. Si la cantidad de información supera esa ventana, la IA puede empezar a "olvidar" las partes más antiguas de la información. Los modelos de IA más nuevos suelen tener ventanas de contexto más grandes. Tess muestra esa información para cada modelo disponible.

Existen dos modos de contexto principales en Tess AI:
Modo Deep Learning (Contenido Corto):
Cómo funciona: Este modo agarra todo el texto del documento y lo mete directamente en la ventana de contexto de la IA para cada consulta. Es como si copiaras y pegaras todo el contenido del documento en el chat cada vez que preguntas algo.
Pros: La IA tiene acceso a todo el contenido del documento en cada respuesta, lo que puede ser bueno para entender textos pequeños de forma completa.
Contras:
Si el documento es muy largo, puede exceder la ventana de contexto de la IA y sólo se analizará una parte del documento.
Para documentos largos, incluso si caben en la ventana, la IA puede “perderse” o tener problema para mantener el enfoque en tu solicitud específica.
La IA vuelve a leer todo el documento en cada interacción, haciendo que sea menos eficiente.
Cuándo usar: Ideal para documentos cortos (por ejemplo, hasta 3-5 páginas, según la cantidad de texto y la ventana de contexto de la IA que elijas). Perfecto para memos, artículos cortos o secciones específicas de hojas de cálculo.
Modo RAG (Retrieval Augmented Generation) (Contenido Largo):
Cómo funciona: RAG es una técnica avanzada. Primero, el documento se procesa una vez: su texto se divide en trozos más pequeños y se “vectoriza” (o sea, se convierte en representaciones numéricas que capturan el significado semántico). Estos vectores se guardan en una base de datos especial, que funciona como un índice inteligente. Cuando haces una pregunta, la IA busca en ese índice los fragmentos (vectores) más relevantes y usa sólo esos fragmentos para crear la respuesta.
Pros:
Es súper eficiente para documentos largos (manuales, libros, bases de conocimiento extensas).
La IA sólo se centra en las partes relevantes, así que las respuestas son más rápidas y precisas para consultas específicas.
Menos probabilidades de exceder la ventana de contexto de la IA, ya que sólo se cargan los fragmentos relevantes.
Contras: La calidad de la respuesta depende de si la IA sabe encontrar los fragmentos adecuados. Cómo esté estructurado el documento puede afectar esto. Si hay info clave que está muy lejos semántica o físicamente de donde la IA busca, puede que se quede fuera.
Cuándo usar: Es la mejor opción para documentos grandes como manuales técnicos, bases de conocimiento de empresas, libros o informes largos.
Tip Práctico sobre RAG y la Estructura del Documento: La eficacia del modo RAG puede mejorarse con la estructura de tu documento. Por ejemplo, en un manual de vacunación, si el título "Gestantes" está muy separado de la lista de vacunas aplicables, la IA puede tener dificultad en asociar una vacuna específica (por ejemplo, "Vacuna de la Gripe") con el público "Gestantes". En esos casos, puede ser útil ajustar el documento para que la información clave (como el público objetivo) esté más cerca de la información detallada (como el nombre de la vacuna y sus especificaciones).
Vamos a ejemplificar el análisis de un libro en PDF, como "Dom Casmurro", usando el modo RAG, que es ideal para documentos largos.
Agregar el PDF:
Haz clic en "Adicionar à Base de Conhecimento".
Agrega el "PDF".
Elige el "Modo de Extracción": "Processamento Standard de Texto" (si el PDF tiene solo texto) o "Processamento de Imagem e Texto" (si tiene imágenes con texto importante).
Selecciona el "Modo de Contexto": RAG Mode (Contenido Largo).

Seleccionar el Modelo de IA:
Puedes elegir un modelo específico (por ejemplo: Claude, Gemini, ChatGPT) o usar "Tess 5", que selecciona automáticamente un modelo ilimitado y adecuado, o "Tess 5 Pro", que puede elegir entre todos los modelos, incluso los que gastan créditos, para tareas más complejas. Para un primer análisis de un libro conocido, "Tess 5" (ilimitado) suele ser suficiente.
Haciendo Preguntas Específicas:
Para asegurarte de que la IA use el documento, sé explícito en tu prompt: "Com base no PDF 'Dom Casmurro.pdf' em sua base de conhecimento, quais são as informações de publicação do livro, como editora, volume e ano de lançamento?"
La IA, usando el modo RAG, va a buscar en el índice del documento los fragmentos que contienen información sobre "publicación", "editorial", "volumen" y "año" y te dará la respuesta.
Solicitando Resúmenes de Partes Específicas:
"Com base no PDF 'Dom Casmurro.pdf', gere um resumo do capítulo 5."
La IA va a encontrar el fragmento del capítulo 5 y lo va a resumir.
Sé específico en los prompts: Al interactuar con documentos, sobre todo si tienes varios en la base de conocimiento, menciona el nombre del archivo en tu petición (ej: "En el documento 'RelatorioAnual.pdf', ¿cuál fue...").
Considera la estructura del documento (para RAG): Títulos claros, información relacionada cerca y buena organización del texto ayudan al modo RAG a encontrar los fragmentos más relevantes.
Prueba diferentes modelos de IA: Si una respuesta no te convence, intenta cambiar el modelo de IA. Algunos se dan mejor con texto, otros con datos. El "Tess 5 Pro" puede ayudarte a encontrar un modelo más robusto si lo necesitas.
Empieza con modelos ilimitados: Para la mayoría de las tareas diarias, "Tess 5" (que usa modelos ilimitados) es muy buena opción. Si necesitas más potencia o precisión para algo concreto, puedes cambiar a un modelo más avanzado para esa interacción.
Límite para Deep Learning: Como regla general, piensa en usar modo Deep Learning para documentos de hasta unas 10-20 páginas. Para volúmenes mayores, RAG suele ser mejor.
Revisa la base de conocimiento: Puedes ver y gestionar los documentos añadidos al hacer clic en la opción para ver la base de conocimiento. [IMAGEN AQUI - Pantalla mostrando la lista de documentos en la Base de Conocimiento]
Los mismos principios de procesamiento de documentos (Deep Learning y RAG) se aplican cuando usas documentos para entrenar o darle contexto a Agentes de IA en el AI Studio. Por ejemplo, al agregar documentos en la base de conocimiento de un agente, generalmente va a usar una lógica similar a la de RAG. Si usas un paso de "Extraer Contenido de Documento" dentro del flujo de un agente, el comportamiento se parece más al Deep Learning, insertando el contenido en la ventana de contexto de ese paso específico. Este es un tema amplio que se puede explorar en más detalle.
La funcionalidad de agregar documentos a la base de conocimiento del AI Copilot en Tess AI cambia la forma en que interactúas con la inteligencia artificial. Al entender los tipos de archivos soportados, los detalles del web scraper y, sobre todo, la diferencia y aplicación de los modos de contexto Deep Learning y RAG, puedes sacar información valiosa, obtener respuestas más precisas y personalizadas, y de verdad aprovechar el conocimiento almacenado en tus propios archivos. Prueba, ajusta las configuraciones y descubre el potencial ilimitado de tener una IA que entiende tu mundo.
