Esta función permite extraer texto de páginas específicas de un documento PDF. Es útil para centrarse en secciones particulares de un documento sin necesidad de procesar el archivo completo, ahorrando tiempo y recursos.
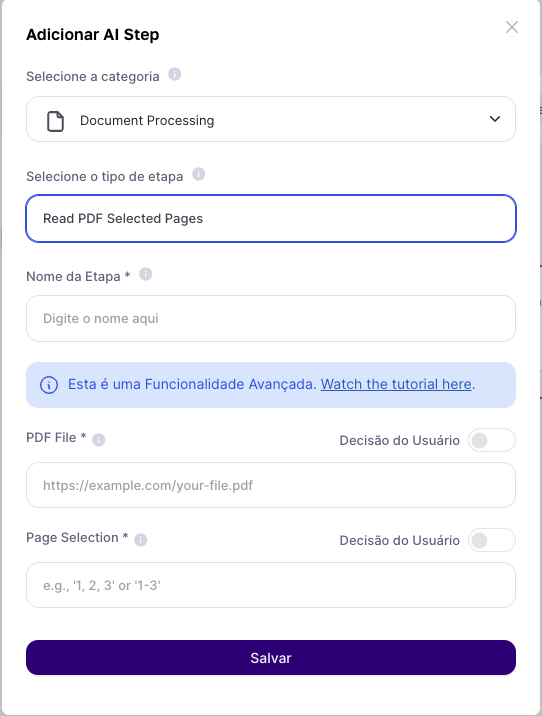
Campos de Relleno:
Inserta el archivo o enlace PDF: Proporciona un enlace a un archivo PDF accesible públicamente. Alternativamente, puedes usar el resultado de la entrada del usuario "Subir Archivo" para extraer datos de archivos almacenados en tu computadora.
Especifica las Páginas: Indica de qué páginas del PDF quieres extraer el texto. Puedes introducir un único número de página, un rango o una lista separada por comas.
Resultado de Output:
Se extraerá el texto de las páginas especificadas.
Casos de Uso:
1. Análisis de Capítulos Específicos: Ideal para estudiantes e investigadores que necesitan analizar capítulos específicos de libros académicos.
2. Revisión de Documentos Legales: Permite a abogados revisar rápidamente cláusulas específicas en contratos extensos.
3. Compilación de Información Sectorial: Facilita la recopilación de información de determinadas secciones de informes anuales o documentos técnicos para análisis de mercado.
Limitaciones:
Es importante tener en cuenta que el entrenamiento de tu IA basado en documentos PDF extraídos por medio de Tess AI tiene una limitación de tamaño.
El entrenamiento no puede superar las 80.000 palabras. Por lo tanto, asegúrate de que el PDF seleccionado esté dentro de este límite. En caso de que tengas un PDF con más de 80.000 palabras, considera dividirlo en partes más pequeñas o seleccionar solo las secciones más relevantes.
Ejemplos de Implementación:
Caso 1: Análisis de Secciones de un Libro: Un usuario carga un PDF de un libro y especifica que solo se lean las páginas del capítulo 3 para centrarse en un tema específico.
Caso 2: Consulta de Cláusulas Contractuales: Un abogado usa un enlace fijo para un contrato y extrae solo las páginas que contienen cláusulas de interés para una revisión rápida.
Conclusión:
La función "Read PDF Selected Pages" es un paso valioso en Tess AI para extraer texto de páginas específicas de documentos PDF, permitiendo un análisis más enfocado y eficiente de la información relevante sin necesidad de procesar documentos completos.
