A capacidade de uma IA manter uma conversa coerente e processar informações depende diretamente de sua "janela de contexto". Na Tess AI ou em qualquer outra plataforma, compreender como essa janela funciona é fundamental para otimizar suas interações, seja em conversas diretas, ao analisar documentos ou ao criar agentes. Este artigo explora o conceito de janelas de contexto, tokens, e como você pode gerenciar esses elementos para obter os melhores resultados na plataforma.
Toda interação com um modelo de IA ocorre dentro de uma "janela de contexto". Pense nela como a memória de curto prazo da IA durante uma conversa ou tarefa específica. Essa memória é medida em tokens. Tokens não são simplesmente palavras; eles são unidades de texto que os modelos de IA utilizam para processar e entender a linguagem. Uma palavra pode ser um token, parte de um token, ou múltiplos tokens, dependendo de sua complexidade e do idioma.
Cada modelo de IA disponível na Tess AI, como as variações do GPT ou Gemini, possui uma capacidade máxima de tokens para sua janela de contexto. Por exemplo, o modelo GPT-4.1 Nano pode suportar até 1 milhão de tokens, enquanto o GPT-4o Mini suporta 128.000 tokens, e alguns modelos Gemini podem chegar a 2 milhões de tokens.
É importante notar que essa contagem de tokens inclui tanto as suas entradas (perguntas, instruções, arquivos enviados) quanto as saídas geradas pela IA (respostas, textos criados).
Quando a quantidade de tokens em uma interação se aproxima ou excede o limite da janela de contexto do modelo selecionado, a IA pode começar a apresentar comportamentos inesperados. Isso pode incluir a perda de informações anteriores da conversa, respostas menos coerentes, ou o que é popularmente chamado de "alucinação" (geração de informações incorretas).
Para auxiliar os usuários, a Tess AI implementou um aviso que surge quando a conversa está se tornando muito longa e se aproximando do limite da janela de contexto, sugerindo a abertura de um novo chat.
Passo a Passo: Verificando a Janela de Contexto de um Modelo
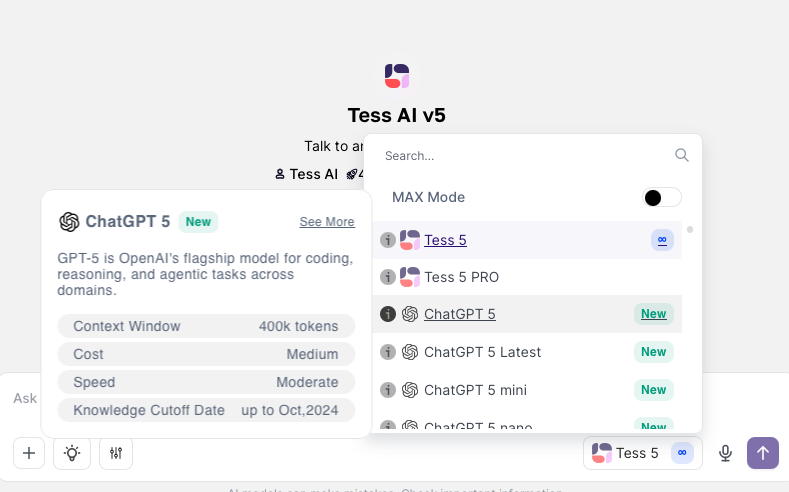
No AI Copilot, na área de conversa, clique no seletor de modelos.
Ao lado do nome do modelo desejado, você verá um pequeno ícone de informação (um "i" dentro de um círculo).
Clique neste ícone para visualizar detalhes do modelo, incluindo sua "Context Window" (Janela de Contexto) em tokens.
Dica: Se você prevê uma interação longa ou a necessidade de fornecer um grande volume de informações, opte por modelos com janelas de contexto maiores desde o início.
Uma das funcionalidades bacanas da Tess AI é a capacidade de analisar arquivos, como PDFs, planilhas (Sheets, Excel) e documentos (Docs). A forma como você sobe esses arquivos na Base de Conhecimento impacta diretamente o uso da janela de contexto.
Ao adicionar um arquivo à Base de Conhecimento, você encontrará duas opções principais no "Modo de Contexto":
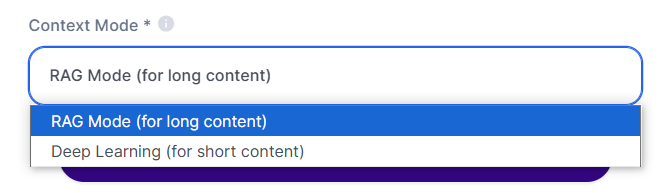
Deep Learning Mode:
Ideal para: Arquivos menores (ex: PDFs de poucas páginas).
Como funciona: A IA faz uma leitura completa do arquivo de uma só vez, incorporando todo o seu conteúdo ao contexto.
Consumo de créditos: Ocorre uma única vez, no momento da leitura integral do arquivo (em torno de 20 créditos)
Impacto na janela de contexto: O conteúdo total do arquivo ocupará uma porção da janela de contexto do modelo.
RAG Mode (RAG - Retrieval Augmented Generation):
Ideal para: Arquivos extensos (ex: PDFs longos, grandes planilhas).
Como funciona: A IA divide o arquivo em múltiplos "pedaços" (chunks). Quando você faz uma pergunta, a IA busca e analisa apenas os trechos relevantes para responder, em vez de processar o arquivo inteiro a cada interação.
Consumo de créditos: Ocorre a cada pergunta que exige a busca e análise de trechos do arquivo. (normalmente bem baixo)
Impacto na janela de contexto: Muito mais eficiente para arquivos grandes, pois apenas os trechos relevantes são carregados no contexto no momento da pergunta, preservando a maior parte da janela para a interação.
Melhor Prática: Para documentos curtos e análises rápidas, o Deep Learning pode ser suficiente. Para documentos volumosos ou quando você precisa consultar partes específicas de um material extenso repetidamente, o RAG Mode é a escolha mais estratégica, pois otimiza o uso da janela de contexto e, potencialmente, o consumo de créditos a longo prazo.
Se você frequentemente realiza tarefas repetitivas que exigem um conjunto específico de instruções ou conhecimento, ou se suas conversas tendem a se estender muito, atingindo os limites de contexto, a criação de um Agente de IA no AI Studio é uma excelente solução.
Ao criar um agente, você fornece instruções detalhadas (prompt) e pode até anexar bases de conhecimento específicas para ele uma única vez. Esse "treinamento" inicial é armazenado no agente.
Como isso ajuda com a janela de contexto? Cada novo chat que você inicia com seu agente personalizado começa com uma janela de contexto "limpa" para a interação em si, mas o agente já possui todo o conhecimento e as diretrizes que você configurou. Isso significa que você não precisa repetir longas instruções a cada nova conversa, economizando tokens e mantendo as interações mais curtas e focadas.
Para aprender a criar um agente, acesse nosso outro artigo!
Se, mesmo com as estratégias acima, você atingir o limite de contexto em um chat e a IA sugerir iniciar uma nova conversa, o histórico da conversa atual não é automaticamente transferido.
Solução Paliativa:
Copie as partes mais importantes da sua conversa anterior.
Inicie um novo chat, preferencialmente com um modelo de IA que possua uma janela de contexto maior.
Cole o histórico copiado no novo chat para fornecer o contexto necessário à IA.
Olhando para o Futuro: A Tess AI está desenvolveu um recurso incrível chamado "Tess Memories", que permite salvar informações e contextos específicos para serem reutilizados em diferentes chats, facilitando a continuidade e a personalização das interações sem a necessidade de copiar e colar manualmente.
Vale a pena testar!
